

Automatiza Backups de MySQL en RDS con Lambda y S3
Apasionado por la tecnología con más de 10 años de experiencia. Actualmente trabajando con tecnologías Cloud y Devops.
☁️ AWS Certified Solutions Architect – Associate ☁️ AWS Certified Security – Specialty
Cuando se utiliza un motor RDS con MySQL para almacenar las bases de datos de distintas aplicaciones, aunque ya estén activados los backups automáticos de AWS en RDS, puede surgir la necesidad de mayor flexibilidad para poder restaurar un backup en caso de que una base de datos puntual falle.
Al utilizar solo los snapshots de RDS, en caso de que una sola base se corrompa, es necesario levantar un snapshot, realizar un backup de la base de datos afectada y luego importar ese dump en el RDS productivo. Este proceso puede ser bastante lento y complicado.
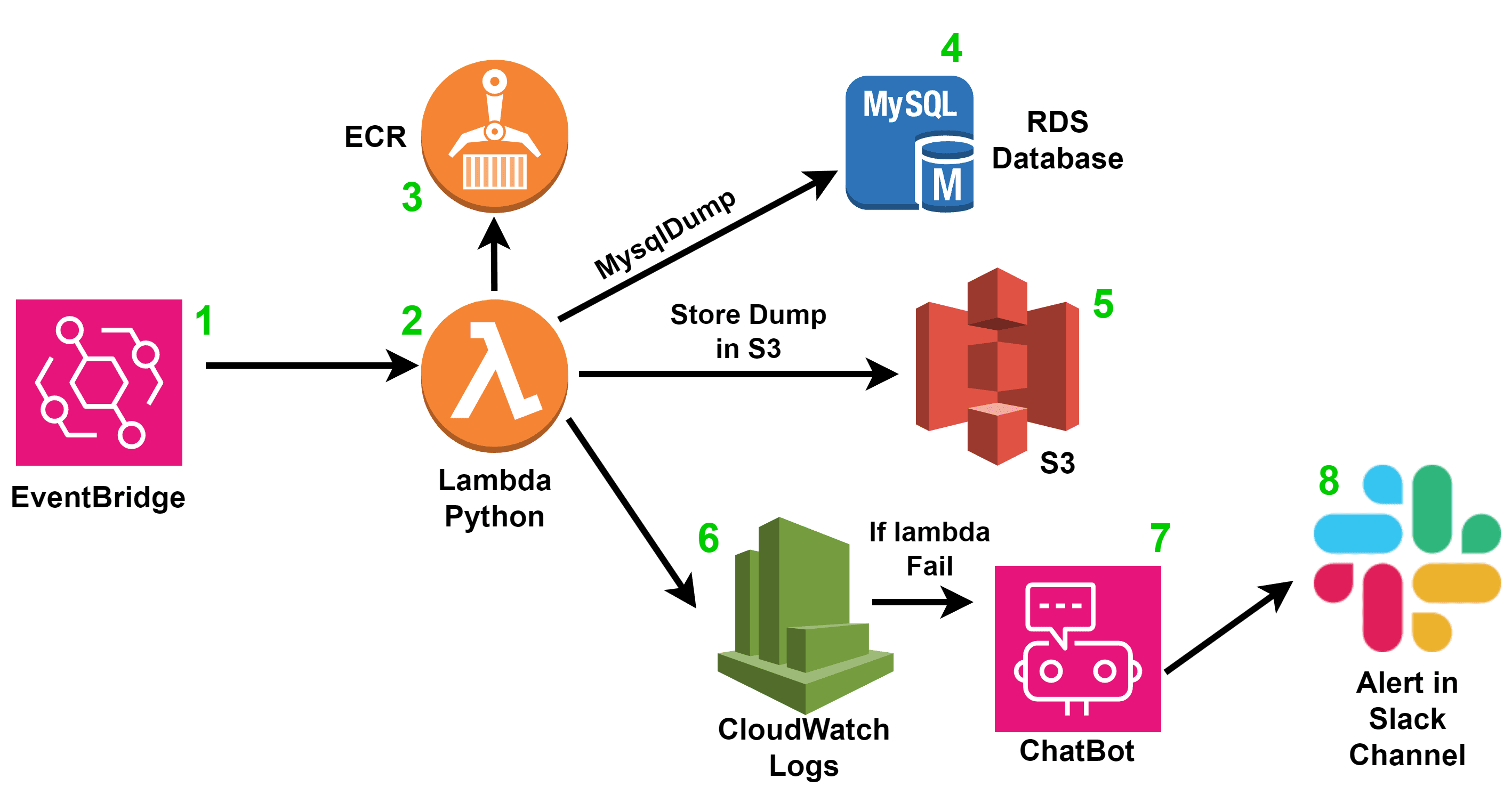
En este artículo, te vamos a mostrar cómo hacer backups de tus bases de datos MySQL en RDS utilizando Lambda y S3, para tener una solución más rápida y flexible. A continuación, detallaremos los pasos necesarios para construir una imagen Docker, subirla a ECR, crear una función Lambda basada en esta imagen, configurar las variables de entorno y las políticas de IAM necesarias, y crear un bucket S3 para almacenar los backups.
Paso 1: Crear la imagen Docker
Primero, crearemos una imagen Docker que se encargará de realizar el backup de la base de datos. Esta imagen debe incluir el cliente MySQL y AWS CLI (viene por defecto en la imagen de AWS) para interactuar con RDS y S3.
Dockerfile:
# Usar la imagen base de AWS Lambda para Python 3.8
FROM public.ecr.aws/lambda/python:3.8
# Instalar dependencias adicionales
RUN yum install -y \
mysql
# Copiar el script de Python al contenedor
COPY backup.py ${LAMBDA_TASK_ROOT}
# Definir el handler
CMD ["backup.lambda_handler"]
Script backup.py:
import os
import subprocess
import boto3
from datetime import datetime, timedelta
def lambda_handler(event, context):
# Variables de configuración (pueden ser definidas como variables de entorno en la Lambda)
RDS_HOST = os.environ['RDS_HOST']
RDS_DB = os.environ['RDS_DB']
RDS_USER = os.environ['RDS_USER']
RDS_PASSWORD = os.environ['RDS_PASSWORD']
S3_BUCKET = os.environ['S3_BUCKET']
S3_PREFIX = os.environ['S3_PREFIX']
# Obtener la hora actual y restar tres horas
TIMESTAMP = datetime.now() - timedelta(hours=3)
# Formatear TIMESTAMP_STR con el formato deseado
TIMESTAMP_STR = TIMESTAMP.strftime("%Y-%m-%d_%H:%M:%S")
# Nombre de archivo de respaldo
FILENAME = f"{RDS_DB}_{TIMESTAMP_STR}.sql"
FILEPATH = f"/tmp/{FILENAME}"
try:
# Realizar mysqldump
dump_cmd = [
"mysqldump",
"-h", RDS_HOST,
"-u", RDS_USER,
f"-p{RDS_PASSWORD}",
"--single-transaction", # Realiza un dump de una transacción única para tablas InnoDB
"--quick", # Asegura una descarga más rápida de la tabla
"--skip-lock-tables", # Evita bloqueos de tabla durante el dump
"--skip-add-locks", # Evita agregar bloqueos alrededor de la sentencia de tabla INSERT
"--skip-comments", # Evita la generación de comentarios en la salida
RDS_DB,
f"> {FILEPATH}"
]
subprocess.run(" ".join(dump_cmd), shell=True, check=True)
# Subir a S3 utilizando AWS SDK para Python (boto3)
s3_client = boto3.client('s3')
s3_client.upload_file(FILEPATH, S3_BUCKET, f"{S3_PREFIX}{FILENAME}")
# Log success message
log_message = f"{datetime.now().isoformat()} Lambda ejecutada sin problemas. Archivo de backup generado: {FILENAME}, hora local: {TIMESTAMP_STR}, bucket: {S3_BUCKET}, subpath: {S3_PREFIX}"
print(log_message)
# Limpiar archivo de respaldo local
os.remove(FILEPATH)
return {
'statusCode': 200,
'body': 'Backup and upload completed successfully'
}
except subprocess.CalledProcessError as e:
error_message = f"mysqldump falló: {str(e)}"
print(error_message)
return {
'statusCode': 500,
'body': error_message
}
except Exception as e:
error_message = f"Ocurrió un error: {str(e)}"
print(error_message)
return {
'statusCode': 500,
'body': error_message
}
Paso 2: Subir la imagen a ECR
Crear un repositorio en ECR:
aws ecr create-repository --repository-name mysqldump
Construir y subir la imagen Docker:
docker build -t mysqldump .
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin AWS-ACCOUNT.dkr.ecr.us-east-1.amazonaws.com
docker tag mysqldump:latest AWS-ACCOUNT.dkr.ecr.us-east-1.amazonaws.com/mysqldump:latest
docker push AWS-ACCOUNT.dkr.ecr.us-east-1.amazonaws.com/mysqldump:latest
Paso 3: Crear el rol de IAM para Lambda
- Crear el rol de ejecución de Lambda:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
- Crear el rol de IAM:
aws iam create-role --role-name lambda-execution-role --assume-role-policy-document file://trust-policy.json
- Attachar la política de permisos al rol:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"rds-db:connect",
"s3:PutObject",
"s3:GetObject",
"s3:ListBucket"
],
"Resource": "*"
}
]
}
- Attachar la política de permisos al rol de IAM:
aws iam put-role-policy --role-name lambda-execution-role --policy-name LambdaRDSBackupPolicy --policy-document file://policy.json
Paso 4: Crear la función Lambda
- Crear la función Lambda basada en la imagen Docker:
aws lambda create-function --function-name RDSBackupFunction \
--package-type Image \
--code ImageUri=<account_id>.dkr.ecr.us-east-1.amazonaws.com/rds-backup:latest \
--role <lambda_execution_role_arn>
- Configurar las variables de entorno:
aws lambda update-function-configuration --function-name RDSBackupFunction \
--environment Variables="{DB_HOST=<db_host>,DB_USER=<db_user>,DB_PASSWORD=<db_password>,DB_NAME=<db_name>,S3_BUCKET=<s3_bucket>}"
Paso 5: Crear el bucket S3
Crear un bucket S3 para almacenar los backups:
aws s3 mb s3://<s3_bucket>
En otros artículos del blog, explicamos cómo configurar los triggers en los log groups de CloudWatch (ya que la lambda registra los errores) para que envíen notificaciones a SNS y cómo configurar AWS Chatbot con Slack para recibir alertas y notificaciones directamente en tus canales de Slack.
Siguiendo estos pasos, hemos creado una solución flexible y rápida para realizar backups de bases de datos MySQL en RDS y almacenarlas en S3. Esta configuración permite tener backups más accesibles y reducir el tiempo de restauración en caso de fallos específicos en las bases de datos. ¡Ahora estás listo para implementar esta estrategia de backup en tu propia infraestructura.



