

Cómo usar AWS S3 Trigger para invocar una Lambda en AWS
Apasionado por la tecnología con más de 10 años de experiencia. Actualmente trabajando con tecnologías Cloud y Devops.
☁️ AWS Certified Solutions Architect – Associate ☁️ AWS Certified Security – Specialty
Los servicios de AWS Lambda y AWS S3 son muy utilizados al momento de desplegar infraestructuras serverless en AWS.
Combinar estos dos servicios por medio de AWS S3 Trigger nos permite ejecutar tareas en tiempo real, al momento en que los archivos ingresan al Bucket S3.
A continuación voy a dar una breve descripción general de cómo funciona la integración y algunos casos de uso potenciales:
Integración entre los servicios:
Configuración de un depósito S3: para realizar esta integración, tenemos que tener ya configurado nuestro bucket S3. Amazon S3 es un servicio de almacenamiento de objetos escalable, donde podemos almacenar la cantidad de datos que deseemos en "contenedores" o buckets.
Eventos de Amazon S3: Dentro de nuestro bucket hay que configurar los eventos por los cuales se va a realizar una posterior tarea (ejecución de lambda). Los eventos más comunes son el ingreso de un objeto al bucket, la eliminación de un objeto, etc.
Función Lambda: Tenemos que tener configurada nuestra Lambda con el código que vamos a ejecutar al ser invocado por el evento de S3.
Disparador S3 para Lambda: En la configuración de nuestra Lambda se configura un disparador para que esta se ejecute cuando recibe un evento de nuestro bucket S3.
Ejecución: Esto sucede cuando el evento que hemos definido en nuestro bucket S3, se captura los detalles del evento y los envía nuestra función Lambda. Luego, la función Lambda procesa este evento en tiempo real.
Casos comunes de uso:
Procesamiento de imágenes: cuando se carga una imagen a un bucket S3, este invoca una lambda para realizar cierto tratamiento con la imagen.
Transformación de datos: cuando se cargan nuevos archivos de datos (CSV, JSON, etc.) en S3, active una Lambda para transformar el formato de datos, limpiarlo o enriquecerlo.
Análisis en tiempo real: analiza los datos entrantes inmediatamente después de la carga. Por ejemplo, analizar archivos de registro a medida que se generan y envían a S3.
Copia de seguridad y archivo: Al recibir un objeto en el bucket, lo podemos mover a otro bucket, mover a Glacier, etc.
Sistema de notificación: Al recibir un archivo podemos hacer que la lambda envíe un mensaje utilizando Amazon SNS.
Validación de contenido: Podemos verificar que el archivo cumple las condiciones necesarias, en caso contrario eliminar el mismo o realizar otro tratamiento.
Actualizaciones de bases de datos: cuando se agregan nuevos datos a S3, una lambda puede leer el contenido e importarlo a Amazon DynamoDB o RDS.
Auditoría y registro: realice un seguimiento de las acciones realizadas en los objetos del depósito de S3 y almacene registros o envíelos a servicios de monitoreo.
En la actualidad es muy común utilizar la integración de S3 y Lambda, combinándola con otros servicios de AWS (por ejemplo, Amazon DynamoDB, Amazon SNS o AWS Step Functions) para crear flujos de trabajo serverless.
Ejemplo de uso:
En este ejemplo vamos a ver los pasos para crear una Lambda y un trigger en un bucket S3 el cual cada vez que se agregue un archivo al bucket, la función Lambda va a ejecutarse y guardar en CloudWatch Logs el tipo de objeto almacenado.
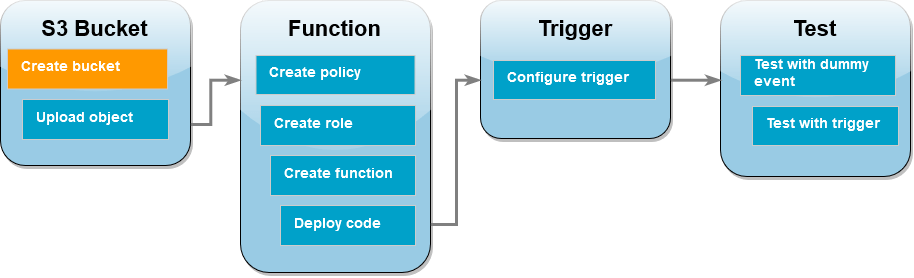
Creamos un bucket de Amazon S3:
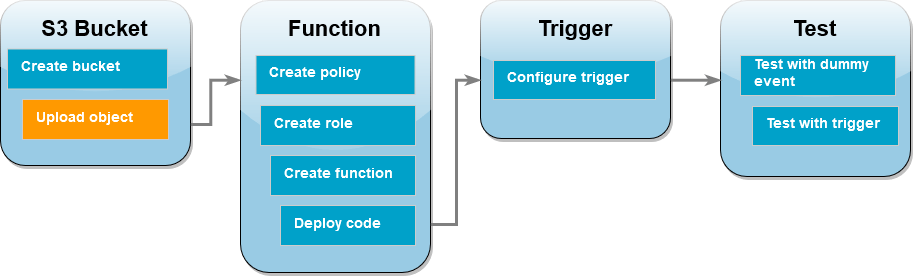
Subimos un archivo a nuestro Bucket:
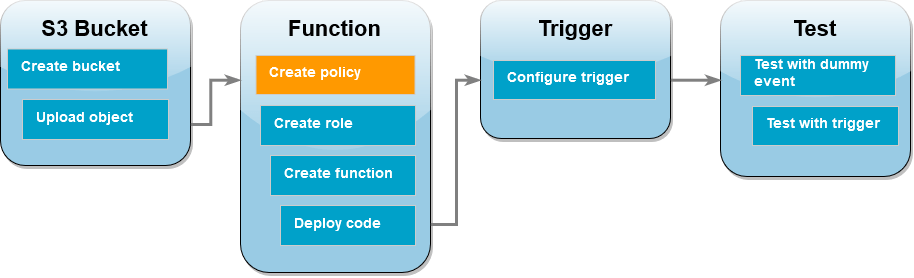
Creamos la siguiente policy de IAM para que la lambda pueda tomar objetos de S3 y escribir en CloudWatch:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:PutLogEvents", "logs:CreateLogGroup", "logs:CreateLogStream" ], "Resource": "arn:aws:logs:*:*:*" }, { "Effect": "Allow", "Action": [ "s3:GetObject" ], "Resource": "arn:aws:s3:::*/*" } ] }Creamos un rol y le attachamos la policy que creamos en el paso anterior:

Creamos la Lambda:

Desplegamos el siguiente código en nuestra lambda:

```plaintext import json import urllib.parse import boto3
print('Loading function')
s3 = boto3.client('s3')
def lambda_handler(event, context):
#print("Received event: " + json.dumps(event, indent=2))
Get the object from the event and show its content type
bucket = event['Records'][0]['s3']['bucket']['name'] key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') try: response = s3.get_object(Bucket=bucket, Key=key) print("CONTENT TYPE: " + response['ContentType']) return response['ContentType'] except Exception as e: print(e) print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket)) raise e
7. Creamos el AWS S3 Trigger:

8. Probamos la integración subiendo un archivo en S3 y vemos el log en CloudWatch:

9. Verificamos en CloudWatch el logstream creado por la Lambda:
```plaintext
Response
"image/jpeg"
Function Logs
START RequestId: 12b3cae7-5f4e-415e-93e6-416b8f8b66e6 Version: $LATEST
2021-02-18T21:40:59.280Z 12b3cae7-5f4e-415e-93e6-416b8f8b66e6 INFO INPUT BUCKET AND KEY: { Bucket: 'my-bucket', Key: 'HappyFace.jpg' }
2021-02-18T21:41:00.215Z 12b3cae7-5f4e-415e-93e6-416b8f8b66e6 INFO CONTENT TYPE: image/jpeg
END RequestId: 12b3cae7-5f4e-415e-93e6-416b8f8b66e6
REPORT RequestId: 12b3cae7-5f4e-415e-93e6-416b8f8b66e6 Duration: 976.25 ms Billed Duration: 977 ms Memory Size: 128 MB Max Memory Used: 90 MB Init Duration: 430.47 ms
Request ID
12b3cae7-5f4e-415e-93e6-416b8f8b66e6
Para concluir, en este simple ejemplo podemos ver la cantidad de opciones que tenemos para automatizar procesos utilizando tecnología serverless con AWS S3 Trigger.
¡Espero que les sirva!
Fuente:
https://docs.aws.amazon.com/es_es/lambda/latest/dg/with-s3-example.html



